最近在試著用 LLM 做一些事情,希望能夠做一些原本是人在處理的事情,發現LLM的智力差別很大。

難免會遇到雲端發生問題,所以在公司內準備最小的地端算力是必要的,因為就寫了一個評分系統。

我的目標是找出翻譯與摘要的能力哪個模型好,於是先叫 Jules 寫一個 CompareModel,效果實在太差了,修了很久還有一堆未完成;只好自己打開 Cursor 寫一個 EvaluateModels,自己靠Claude Sonnet 4 寫大概2小時就完成。
直接說結論吧,我使用 GPT-4.1 和 GPT-4o 、Gemini-2.5-flash 評分都是亂七八糟,地端模型明明寫英文都還評分說有確實寫繁體中文,這3個模型都一樣。

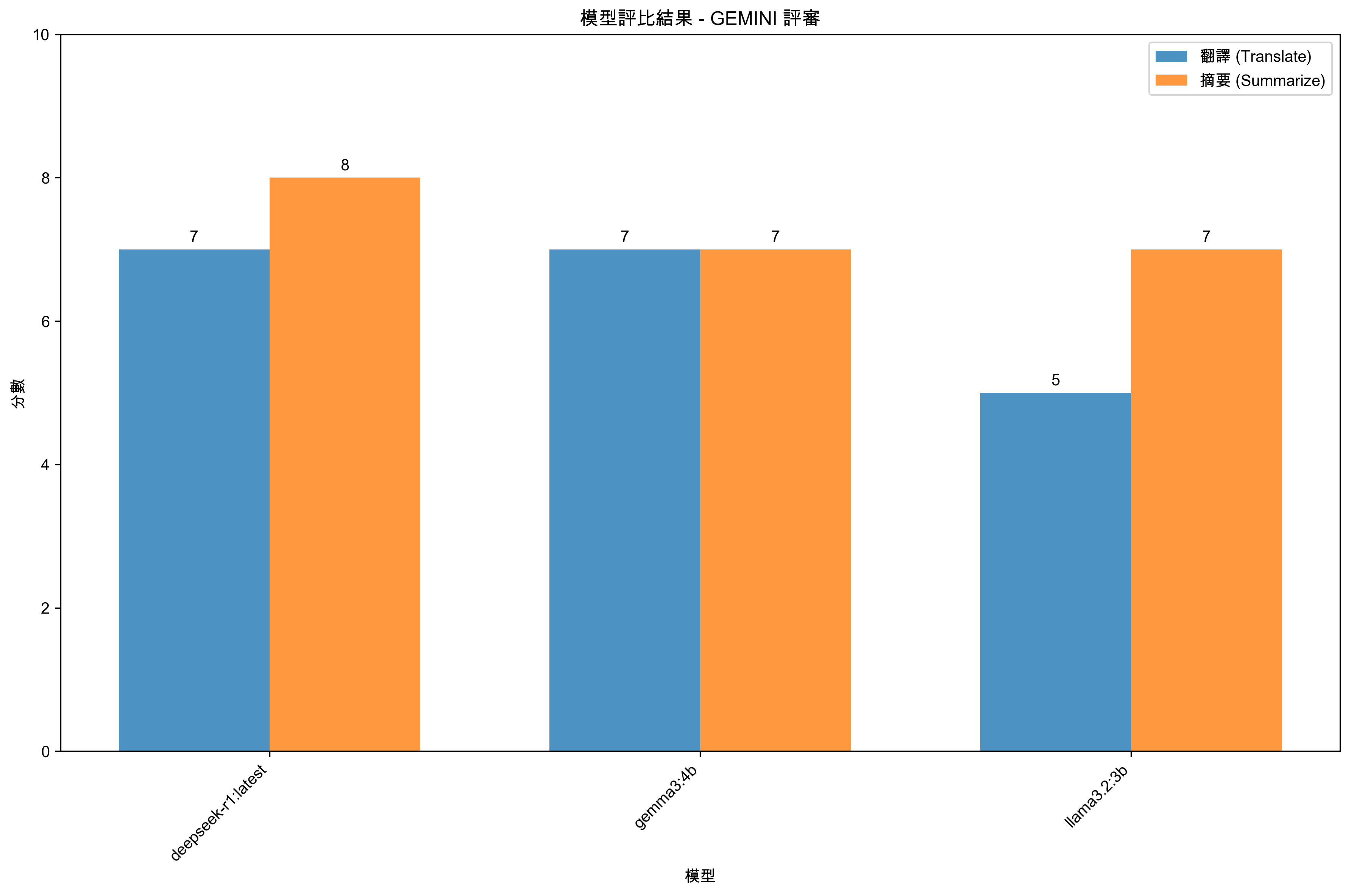
所以後來受不了決定要用 o3 和 Gemini-2.5-Pro,結果就遇到 OpenAI API 400錯誤,只有 Gemini-2.5-Pro 成功,但是 評分結果就很令人滿意👍。


但是我看到帳單後,就高興不起來,高階模型實在太貴了,再多跑幾次我就要破產,所以還要再加上快取結果的功能,不要再讓LLM對相同的輸入重覆運行。希望有個聰明的朋友來協助我做這個改版,現在也只能先找 Cursor 幫忙。
留言